[통계] 통계 테스트용 문항
2024. 1. 21. 23:43ㆍData Science/Study 자료
정규성 검정
- 시나리오: 어느 회사의 직원들의 월급 데이터가 있다. 이 데이터가 정규 분포를 따르는지 확인하고 싶다. 주어진 월급 데이터를 사용하여 정규성 검정을 수행하고 결과를 해석하기
- 가설설정
- 귀무가설 :
- 대립가설 :
- 코드 작성 후 p-value 값을 구하시고 정규성 여부를 조건문으로 구하세요
- 귀무가설, 대립가설, 정규성 만족 유무 print() 만들기 (형식 자유)
- 예) print("abc 만족합니다!")
salaries = [3500, 4000, 4000, 4500, 5000, 5000, 5500, 6000, 6500, 7000]
귀무가설 : 데이터는 정규성을 만족합니다.
대립가설 : 데이터는 정규성을 만족하지 않습니다.
from scipy import stats
t_statistic, p_value = stats.shapiro(salaries)
t_statistic, p_value
if p_value >= 0.05:
print("귀무가설 : 데이터는 정규성을 만족합니다!")
else:
print("대립가설 : 데이터는 정규성을 만족하지 않습니다!")귀무가설 : 데이터는 정규성을 만족합니다!
scipy 라이브러리의 .shapiro 통해서 t통계량과 p벨류 값을 쉽게 구할 수 있었다.
단일 표본 T 검정
- 주어진 데이터(data/trees.csv)에는 블랙 체리나무 31그루의 둘레와 높이, 부피가 저장되어 있다. 이 표본의 평균(Height)이 모평균과 일치하는지 단일표본 t-검정(One Sample t-test)을 통해 답하고자 한다. 가설은 아래와 같다.
- 가설검정
- 귀무가설 : 평균은 75이다.
- 대립가설 : 평균은 75가 아니다.
- 데이터의 변수
- Girth : 둘레
- Height : 높이
- Volume : 부피
- 단, 데이터의 각 변수들은 정규 분포를 만족한다고 가정한다.
- 문제 1 : 표본평균 X를 구하시오. (반올림하여 소숫점 둘째 자리까지 계산)
- 문제 2 : 위의 가설을 검정하기 위한 검정통계량을 구하시오. (반올림하여 소숫점 둘째 자리까지 계산)
- 문제 3 : 위의 통계량에 대한 p-값을 구하고(반올림하여 소숫점 넷째 자리까지 계산), 유의수준 0.05하에서 가설검정의 결과를 채택/기각 중 하나로 선택하시오.
- p-value에 값에 따른 결괏값을 조건문(if-else)으로 구하세요.
데이터 불러오기
import pandas as pd
df = pd.read_csv("./data/trees.csv")
df.head()
문제 1
- 표본평균 Height X를 구하시오. (반올림하여 소숫점 둘째 자리까지 계산)
# 코드
result = df['Height'].mean()
round(result, 2)76.0round(,)함수를 통해서 반올림을 해줄 범위를 설정할 수 있다.
문제 2
- 위의 가설을 검정하기 위한 검정통계량을 구하시오. (반올림하여 소숫점 둘째 자리까지 계산)
# 코드
from scipy import stats
from math import sqrt
t_score, p_value = stats.ttest_1samp(df['Height'], popmean=75)
print(round(t_score, 2), round(p_value, 2))0.87 0.39scipy라이브러리에서 단일표본 t검정 매소드를 찾아서 사용하면된다.
ttest_1samp( 데이터, 표본평균)
문제 3
- 위의 통계량에 대한 p-값을 구하고(반올림하여 소숫점 넷째 자리까지 계산), 유의수준 0.05하에서 가설검정의 결과를 채택/기각 중 하나로 선택하시오.
# 코드
print(round(p_value, 4))
if p_value >= 0.05:
print("채택")
else:
print("기각")0.3892
채택
대응표본 T검정

import pandas as pd
df = pd.read_csv("./data/insectsprays.csv")
df.head()

diff = df['after_spr'] - df['before_spr']
print(round(diff.mean(), 2))-12.0
문제 2
- 위의 가설을 검정하기 위한 검정통계량을 구하시오. (반올림하여 소숫점 둘째 자리까지 계산)
from scipy import stats
from math import sqrt
t_score, p_value = stats.ttest_rel(df['before_spr'], df['after_spr'])
print(round(t_score, 4), round(p_value, 4))14.8933 0.0대응표본 T검정을 진행하기위해 ttest_rel()함수를 사용해준다.
문제 3.
- 위의 통계량에 대한 p-값을 구하고 (반올림하여 소숫점 넷째 자리까지 계산), 유의수준 0.05하에서 가설검정의 결과를 채택/기각 중 하나로 선택하시오.
- p-value에 값에 따른 결괏값을 조건문(if-else)으로 구하세요.
print(round(p_value, 4))
if p_value >= 0.05:
print("채택")
else:
print("기각")0.0
기각

데이터 불러오기
import pandas as pd
df = pd.read_csv("./data/toothgrowth.csv")
df.head()
등분산성 검정¶
- 독립표본 T-검정은 정규성 검정 뿐만 아니라, 두 그룹이 등분산성을 띠는지 확인하는 작업 필요
- Levene 검정을 사용한 등분산성 검정이 선행되어야 함
- stats.levene() 함수 활용. 라이브러리 링크 : https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.levene.html
- 가설설정
- 귀무가설 :두 그룹은 등분산성의 차이가 없다
- 대립가설 :두 그룹은 등분산성의 차이가 있다
- pvalue 값 : 0.2751764616144053
from scipy import stats
stats.levene(df.loc[df['supp'] == "VC", 'len'], df.loc[df['supp'] == "OJ", 'len'])LeveneResult(statistic=1.2135720656945064, pvalue=0.2751764616144052)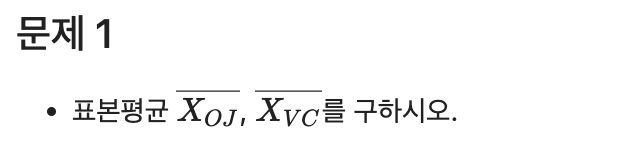
OJ_result = df.loc[df['supp'] == "OJ", 'len'].mean()
round(OJ_result, 2)20.66VC_result = df.loc[df['supp'] == "VC", 'len'].mean()
round(VC_result, 2)16.96
문제 2
- 위의 가설을 검정하기 위한 검정통계량을 구하시오. (반올림하여 소숫점 둘째 자리까지 계산)
from scipy import stats
from math import sqrt
t_score, p_value = stats.ttest_ind(df.loc[df['supp'] == "VC", 'len'],
df.loc[df['supp'] == "OJ", 'len'], equal_var = True)
print(round(t_score, 4), round(p_value, 2))-1.9153 0.06등분산성검정을 할때는 scipy 라이브러리의 ttest_ind()메소드를 사용한다.
문제 3.
- 위의 통계량에 대한 p-값을 구하고 (반올림하여 소숫점 넷째 자리까지 계산), 유의수준 0.05하에서 가설검정의 결과를 채택/기각 중 하나로 선택하시오.
- p-value에 값에 따른 결괏값을 조건문(if-else)으로 구하세요.
print(round(p_value, 4))
if p_value >= 0.05:
print("채택")
else:
print("기각")0.0604
채택'Data Science > Study 자료' 카테고리의 다른 글
| [Streamlit] st.write/ 마크다운 사용하기 (0) | 2024.01.29 |
|---|---|
| 내가 보려고 만드는 기본 리눅스 명령어 정리 (0) | 2024.01.23 |
| [통계] 회귀분석 (0) | 2024.01.12 |
| [통계] 독립표본 t검정, 대응 표본 t검정 (0) | 2024.01.11 |
| [통계] 통계적 가설검정 (0) | 2024.01.11 |