2024. 4. 17. 16:42ㆍData Science
VM시작하기
인스턴트 만들기
지역 서울 설정
가격에 따른 머신 구성 선택
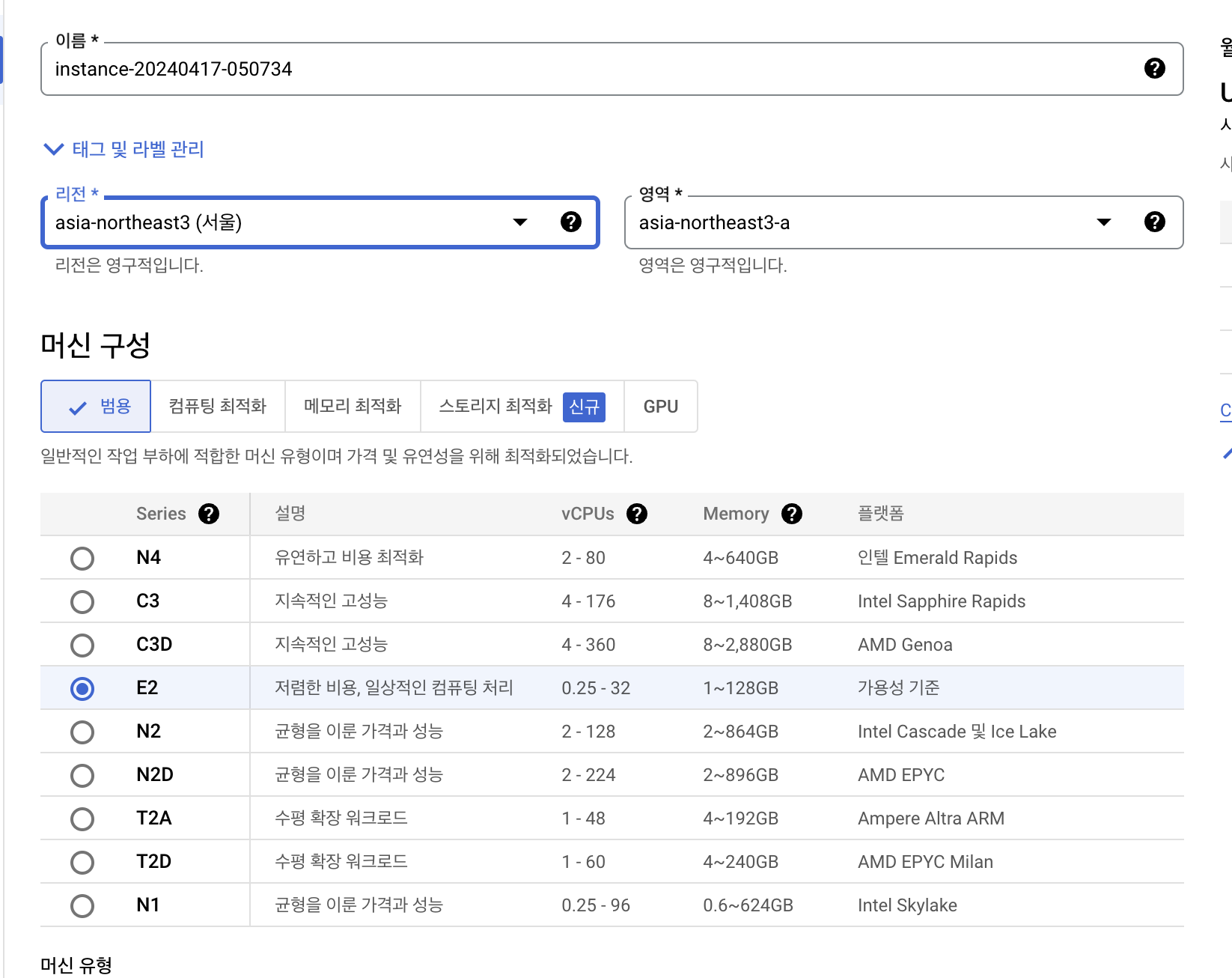
머신유형 선택

부팅디스크에서 운영체제를 Ubuntu로 변경

방화벽은 HTTP,HTTPS 트레픽 허용체크

만들기 클릭

네트워크 보안
- 프로젝트 배포를 진행하기위해서 방화벽을 열어주어야 함
네트워크 세부정보 보기 클릭
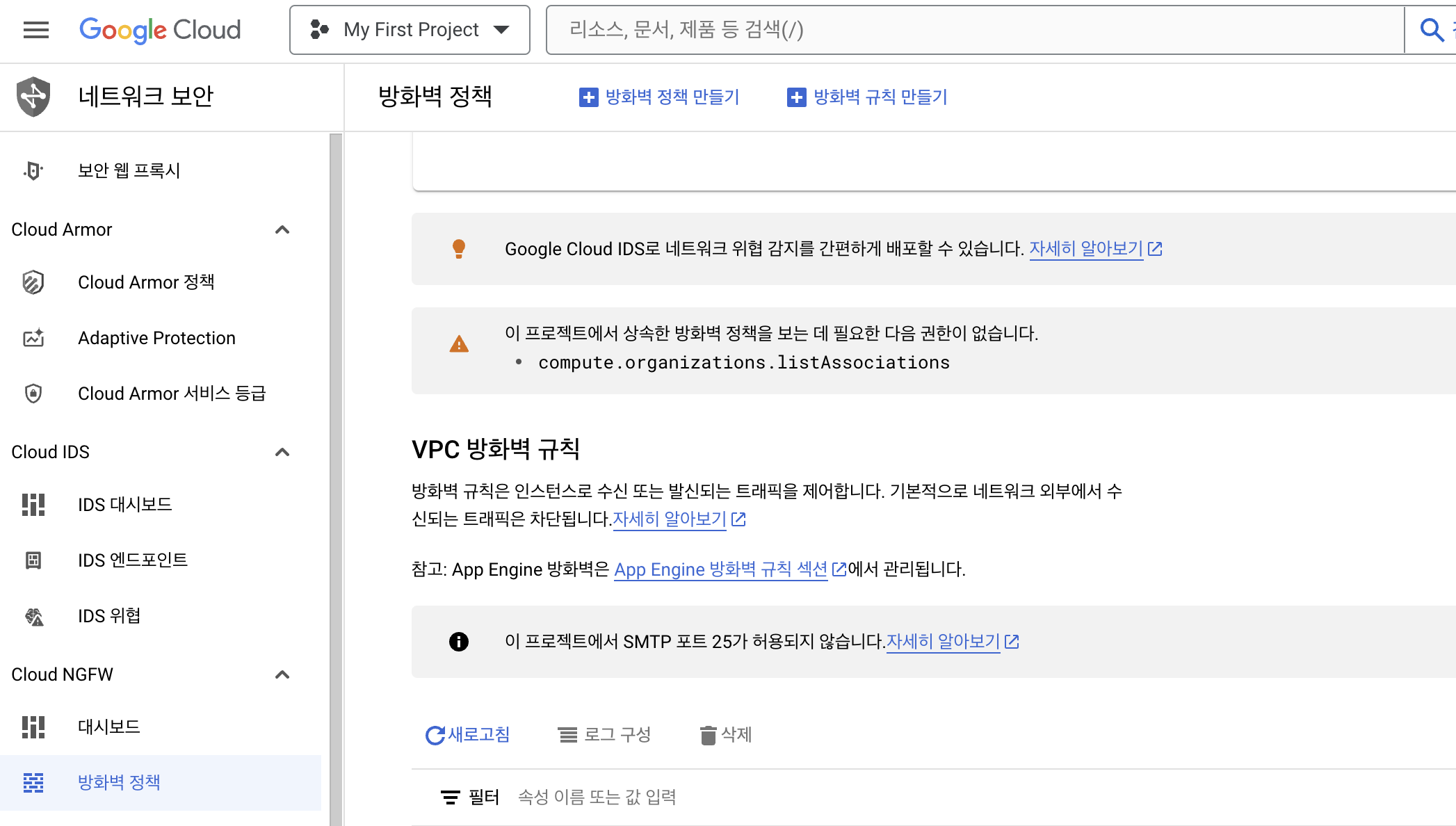
방화벽 규칙 만들기
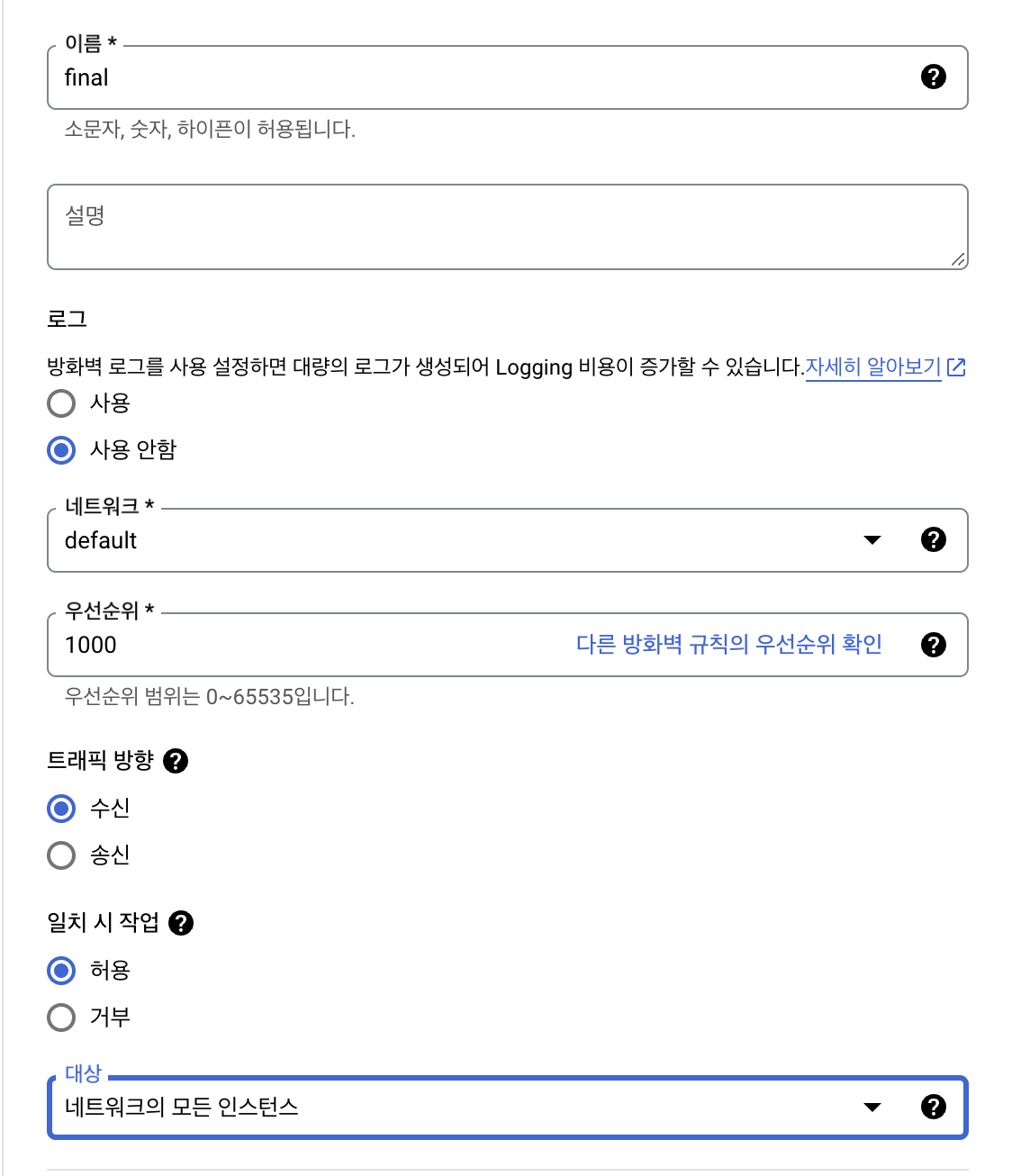
로그 사용안함
대상 네트워크의 모든 인스턴스

소스IPv4범위 0.0.0.0
프로토콜 및 포트 모두허용
개발환경 설치

SSH버튼을 클릭 -> 브라우저 창에서 열기 선택
-개발환경 설정
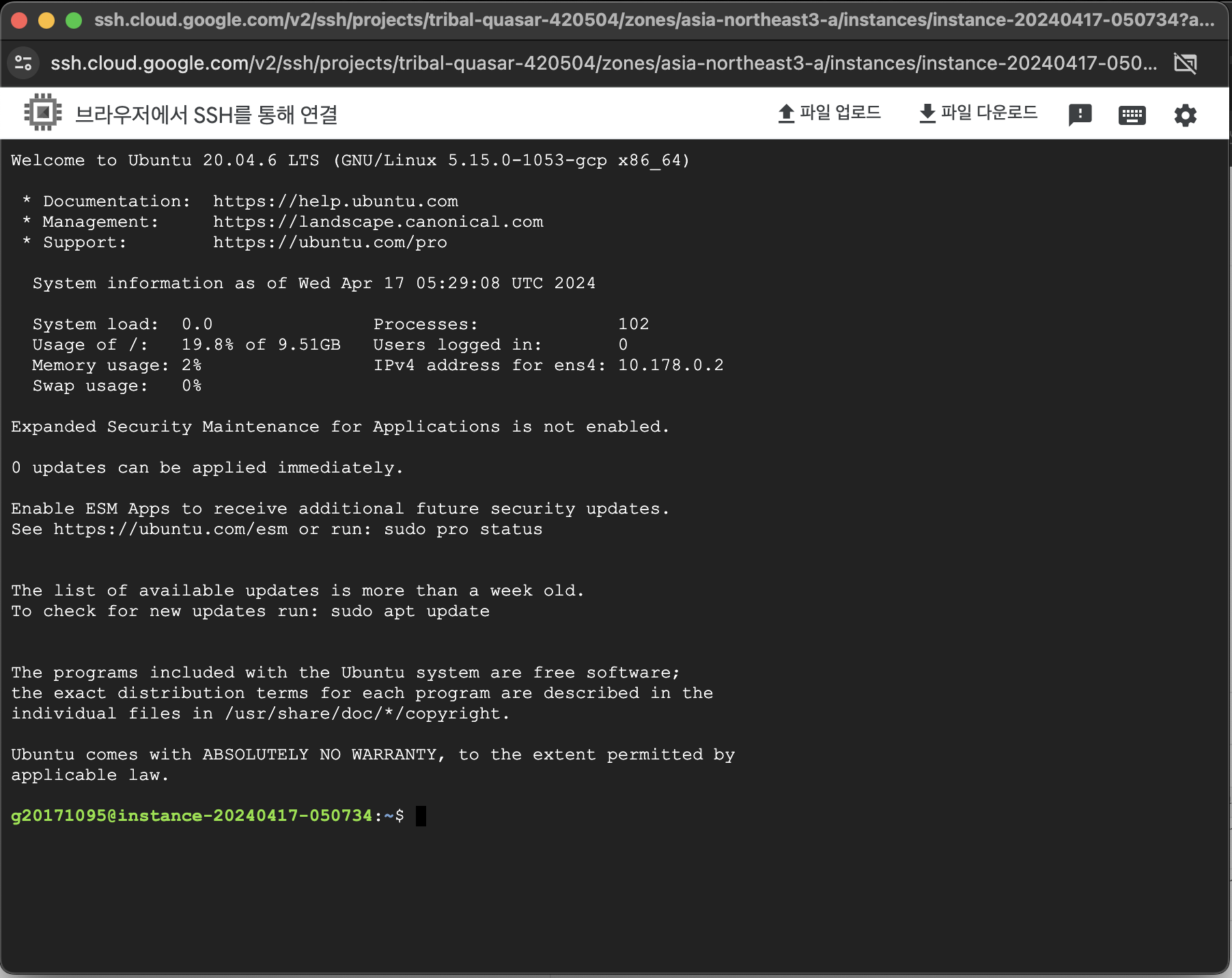
miniconda 설치
먼저 경로를 cd opt로 이동
cd ../../opt설치를 진행(참조: https://docs.conda.io/projects/miniconda/en/latest/)
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh설치후에 아래 명령어들을 입력
~/miniconda3/bin/conda init bash
~/miniconda3/bin/conda init zsh브라우저를 종료하고 다시 브라우저창을 열어준다

(base)가 붙어서 뜨면 정상적으로 설치가 완료
JAVA 설치
(base) /opt$ sudo apt update
(base) /opt$ sudo apt install openjdk-8-jdk -y하나씩 입력해 설치
- JAVA 환경변수 설정을 위해 vi ~/.bashrc 명령어를 실행하여 파일을 열고 아래와 같이 코드를 추가한다.
# JAVA ENV SET
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
export CLASS_PATH=$JAVA_HOME/lib:$CLASS_PATH

가장 하단으로 내려서 추가해준다

INSERT모드에서 ESC를 눌러서 나온후 :wq!를 통해 저장하고 다시 터미널로 돌아올 수 있다
스칼라설치
(base) /opt$ sudo apt-get install scala -y- 스칼라 환경변수 설정을 위해 vi ~/.bashrc 명령어를 실행하여 파일을 열고 아래와 같이 코드를 추가한다.(자바와 동일)
# SCALA ENV SET
export SCALA_HOME=/usr/bin/scala
export PATH=$SCALA_HOME/bin:$PATH
스파크 설치
(base) /opt$ sudo wget https://archive.apache.org/dist/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
(base) /opt$ sudo tar xvf spark-3.1.1-bin-hadoop2.7.tgz
(base) /opt$ sudo mkdir spark
(base) /opt$ sudo mv spark-3.1.1-bin-hadoop2.7/* /opt/spark/
(base) /opt$ cd spark
(base) /opt/spark$ ls
- 스파크환경변수 설정을 위해 vi ~/.bashrc 명령어를 실행하여 파일을 열고 아래와 같이 코드를 추가한다.(자바와 동일)
# SPARK ENV SET
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_PYTHON=/home/your_id/miniconda3/bin/pythonPyspark 설치
환경변수 설정이 끝난 후, pyspark 버전에 맞춰서 설치를 한다
(base) /opt$ pip install pyspark==3.1.1Pyspark 실행을 해본다
명령어 pyspark

exit()로 나갈 수 있다
jupyter Notebook 설치 및 설정
주피터 노트북 설치
(base) $ conda install jupyter notebook
jupyter설정을 위해 config파일을 생성-> vi편집기 실행
(base) $ jupyter notebook --generate-config
Writing default config to: /home/your_id/.jupyter/jupyter_notebook_config.py
(base) $ cd /home/your_id/
(base) $ vi ~/.jupyter/jupyter_notebook_config.py
- vi 편집기에서 찾기는 / 이후 검색을 한다.
- 검색 후, 맞는 문자열이 나오면 Enter + i 를 누르면 수정이 가능하다.
## Whether to allow the user to run the notebook as root.
#c.NotebookApp.allow_root = False
c.NotebookApp.allow_root = True
## The IP address the notebook server will listen on.
c.ServerApp.ip = 'localhost'
c.ServerApp.ip = '0.0.0.0'
Jupyter Notebook을 실행한 후, 외부 IP주소:8888를 URL에 입력하면 접속이 가능하다.
-----추가-----
스파크 버전 변경
pip uninstall pysparkcd/ opt/opt로 경로를 이동
sudo rm -rf *opt에 있는 모든 폴더를 삭제
sudo wget -q https://dlcdn.apache.org/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgzsudo tar -zxf spark-3.5.1-bin-hadoop3.tgzsudo mkdir sparksudo mv spark-3.5.1-bin-hadoop3/* /opt/spark
cd spark
cd $HOME
pip install pyspark==3.5.1
'Data Science' 카테고리의 다른 글
| [GCP] Git 연동방법 (0) | 2024.04.18 |
|---|---|
| [QGIS] 격자데이터 K-means Clustering (0) | 2024.03.29 |
| 분류모형 성과평가 오분류표 (0) | 2024.02.20 |
| [Python] PyCaret 설치 (1) | 2024.02.14 |